✍ David Heras · somosoptia.com ⏱ 8 min de lectura
Seguramente ya has oído hablar de ChatGPT, de modelos de IA y de automatizar procesos con lenguaje natural. Pero cuando intentas entender qué hay detrás, te encuentras con una sopa de siglas: LLM, SLM, MLM… y no siempre está claro qué significa cada una ni, sobre todo, cuál te interesa a ti como empresa.
Este post es una guía práctica para responsables de IT y directores de pyme que quieren tomar decisiones informadas. Sin hype, sin sobreprometer: qué es cada cosa, para qué sirve en una empresa española y qué opciones reales tienes si quieres dar el paso.
Primero lo primero: ¿qué es un modelo de lenguaje?
Un modelo de lenguaje es un sistema de inteligencia artificial entrenado para procesar y generar texto. Puede responder preguntas, resumir documentos, clasificar correos, redactar propuestas o extraer datos de una factura. Su «inteligencia» viene de haber aprendido patrones a partir de enormes cantidades de texto.
La diferencia entre los distintos tipos no está en lo que hacen, sino en el tamaño, el coste y dónde se ejecutan.
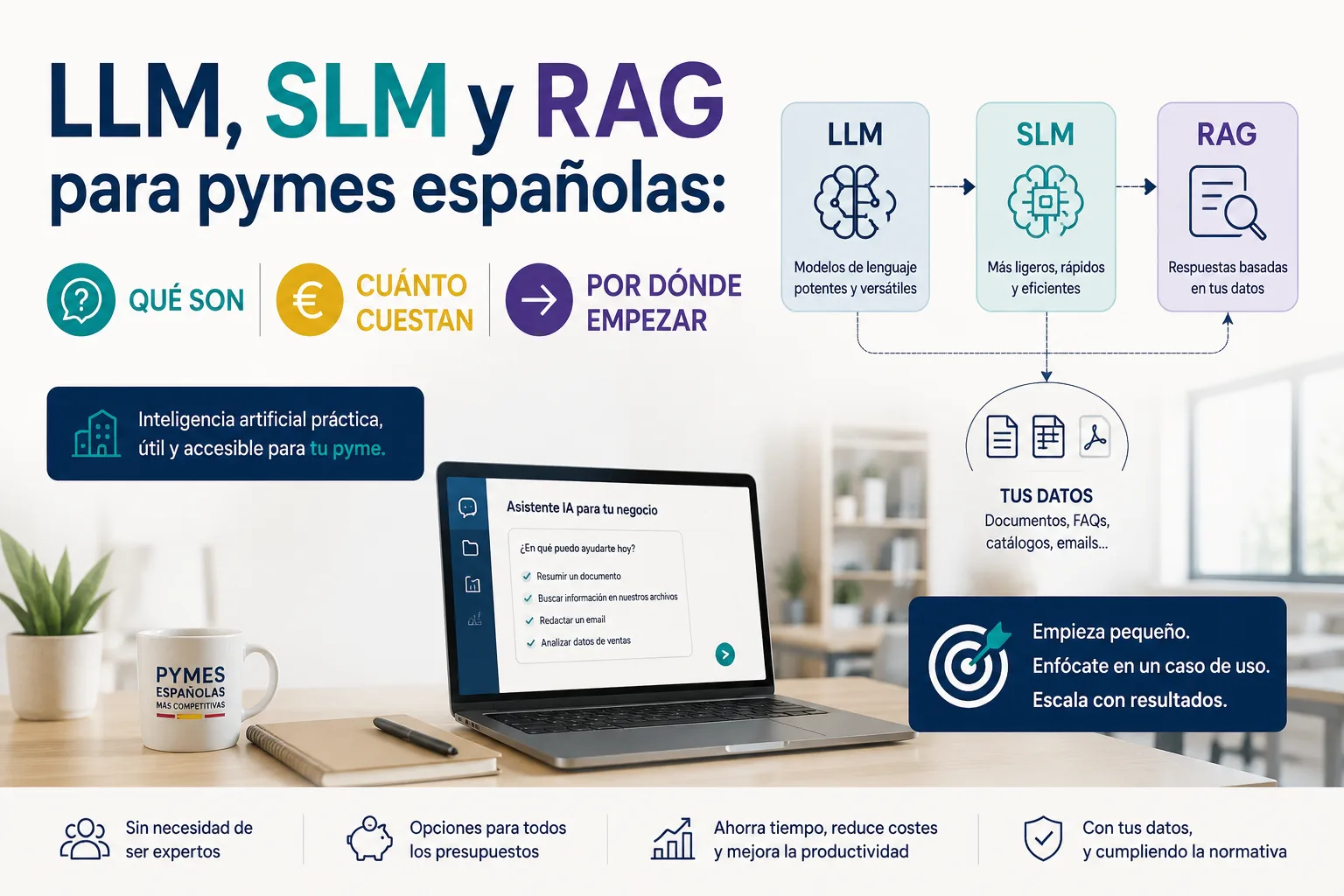
LLM, SLM y MLM: las diferencias que importan
LLM — Large Language Model (Modelo de Lenguaje Grande)
Son los modelos más potentes y conocidos: GPT-4, Claude, Gemini. Tienen cientos de miles de millones de parámetros y son capaces de razonar sobre problemas complejos, generar contenido de alta calidad y mantener conversaciones largas con mucho contexto.
El problema para una pyme: coste por consulta (APIs de pago), latencia, y el hecho de que tus datos salen de tu empresa hacia servidores externos. Para tareas puntuales de alto valor funcionan muy bien. Para procesar miles de documentos internos cada mes, el coste escala rápido.
SLM — Small Language Model (Modelo de Lenguaje Pequeño)
Son modelos mucho más compactos —entre 1.000 millones y 14.000 millones de parámetros— diseñados para ejecutarse con menos recursos. No llegan al nivel de razonamiento de un GPT-4, pero para tareas concretas y bien definidas rinden extraordinariamente bien.
Por qué interesan a las pymes: se pueden ejecutar en hardware propio o en un VPS económico, los datos no salen de tu infraestructura, el coste por consulta es mínimo y se pueden ajustar con tus propios datos (fine-tuning).
Modelos más destacados en 2025–2026:
- Qwen 2.5 7B — Excelente rendimiento en español y entornos multilingües. Mejor equilibrio calidad/coste para empresas.
- Phi-4 (Microsoft) — Licencia MIT, ideal para pruebas y producción ligera sin restricciones de uso comercial.
- Gemma 3 4B / 12B (Google) — Versiones compactas que se ajustan bien a hardware económico, con variantes multimodales.
MLM — Multimodal Language Model (Modelo Multimodal)
Son modelos que no solo procesan texto, sino también imágenes, audio, tablas y PDFs con contenido visual. GPT-4o y Gemini 1.5 Pro son los más conocidos. Algunos SLM ya incorporan capacidades multimodales en versiones compactas.
¿Cuándo los necesita una pyme? Si quieres procesar facturas escaneadas, catálogos en PDF con imágenes o planos técnicos. Para la mayoría de los casos de uso internos —buscador de procedimientos, asistente de soporte, clasificación de correos— un SLM de texto puro es suficiente y mucho más económico.
¿Qué arquitectura encaja con una pyme española?
El error más habitual es empezar con la pregunta equivocada. No es «¿qué modelo instalo?» sino «¿qué problema quiero resolver y qué arquitectura lo resuelve mejor?»
Para la mayoría de pymes, la arquitectura más práctica combina tres capas:
- Modelo base (SLM) — El motor que razona y redacta. No necesitas entrenar uno desde cero; partes de uno ya entrenado y lo adaptas a tu caso.
- RAG (Retrieval-Augmented Generation) — El modelo consulta tus documentos, procedimientos o base de datos antes de responder. Sin RAG, el modelo solo sabe lo que aprendió en su entrenamiento; con RAG, sabe lo que tú le das.
- Capa de integración y gobernanza — Conectores con tu ERP, CRM, Google Drive o SharePoint. Control de accesos, trazabilidad de consultas y límites de uso definidos por ti.
El resultado es un asistente interno que responde sobre tus datos, sin exponer información sensible a APIs externas y con un coste mensual predecible desde el primer día.
Casos de uso con ROI real para pymes
Los SLM no son «el GPT de toda la empresa desde el primer día». Funcionan mejor en tareas repetitivas, acotadas y con volumen. Estos son los que generan más retorno:
- Buscador interno inteligente — Consultas sobre procedimientos, presupuestos, contratos y documentación. El equipo deja de perder tiempo navegando carpetas.
- Asistente de soporte de primer nivel — Responde FAQs de clientes y escala los casos complejos a una persona. Reduce la carga en atención al cliente sin eliminar el trato humano.
- Extractor de datos estructurados — Lee facturas, pedidos y contratos en PDF y vuelca los campos clave a tu sistema. Elimina introducción manual.
- Ayudante comercial — Resume reuniones, prepara propuestas a partir de plantilla y redacta seguimientos de correo. El equipo de ventas recupera horas cada semana.
- Clasificación y triaje de correos — Enruta automáticamente los emails entrantes según urgencia, tipo o departamento.
Costes orientativos: cuánto cuesta montarlo
| Escenario | Coste de implantación | Infraestructura mensual |
|---|---|---|
| Piloto básico (RAG sobre documentación interna) | 2.000 – 6.000 € | 50 – 100 €/mes |
| RAG corporativo con integraciones (Drive, ERP) | 4.000 – 10.000 € | 100 – 250 €/mes |
| Proyecto completo con fine-tuning y flujos automatizados | 10.000 – 30.000 € | 200 – 500 €/mes |
| Formación interna del equipo | 500 – 2.500 € | — |
El coste oculto que nadie menciona: tiempo del equipo para limpiar datos, definir casos de uso y mantener el sistema. Reserva entre un 20% y un 30% del presupuesto total para esto. Los proyectos que fracasan casi siempre lo hacen por subestimar esta partida, no por el modelo elegido.
Infraestructura: ¿necesito un servidor potente?
Para empezar, no. Un modelo como Qwen 2.5 7B o Phi-4 puede correr en un servidor con 16–32 GB de RAM sin GPU dedicada, con latencia aceptable para consultas internas no masivas. Las herramientas más usadas para desplegar estos modelos:
- Ollama — Levanta modelos localmente con un solo comando. Ideal para pilotos y entornos de prueba.
- vLLM — Mayor rendimiento en producción cuando hay varios usuarios simultáneos.
- Qdrant o Pinecone — Bases de datos vectoriales para el componente RAG.
- LangChain o equivalente — Capa de orquestación que conecta el modelo con tus fuentes de datos.
Si el caso de uso es interno y la carga no es intensiva, un VPS de 60–80 €/mes es suficiente para empezar. No inviertas en hardware propio hasta que el piloto haya demostrado valor.
Cómo empezar sin equivocarte
La mayoría de proyectos de IA en pymes fracasan por las mismas razones: empezar por la tecnología en lugar de por el problema, subestimar la calidad de los datos y no tener claro quién mantiene el sistema después. La secuencia que recomendamos desde Somos Optia:
- Define un caso de uso con ahorro medible — no «queremos usar IA», sino «queremos reducir el tiempo de respuesta a consultas internas de 4 horas a 15 minutos».
- Monta RAG antes que fine-tuning — el 80% del valor viene de dar al modelo acceso a tus documentos, no de reentrenarlo.
- Empieza con Qwen 2.5 7B o Phi-4 — mejor balance calidad/coste para español hoy mismo.
- Mide desde el día uno — tiempo ahorrado, tasa de respuestas correctas, satisfacción del equipo.
- Escala solo si el piloto demuestra ROI — no inviertas 30.000 € en algo que no ha demostrado funcionar a pequeña escala.
Riesgos que no puedes ignorar
- Alucinaciones — Sin RAG bien construido, el modelo puede inventar respuestas con confianza. Necesitas mecanismos de validación antes de ponerlo en manos del equipo.
- Privacidad y RGPD — Necesitas saber qué datos entran al modelo, dónde se procesan y quién tiene acceso. Especialmente crítico si manejas datos de clientes o empleados.
- Calidad de datos — Documentos desactualizados, mal estructurados o en varios formatos degradan la calidad de las respuestas. El modelo no mejora datos malos; los amplifica.
- Dependencia técnica — Si nadie en tu empresa entiende el sistema, cualquier incidencia se convierte en un cuello de botella costoso.
¿Quieres saber si un SLM tiene sentido para tu empresa?
En Somos Optia ayudamos a pymes españolas a implementar IA de forma práctica, con las herramientas que ya usan y resultados medibles desde la primera semana. Sin proyectos sobredimensionados ni tecnología por tecnología.
Preguntas frecuentes
Referencias
- Javadex — Small Language Models (SLM): tendencia 2026, guía completa
https://www.javadex.es/blog/small-language-models-slm-tendencia-2026-guia-completa - Aimoova — Stack de IA local para pymes y autónomos: Ollama, LangChain y RAG
https://www.aimoova.com/post/pymes-autonomos-stack-ia-local-ollama-langchain-rag - IA4Pymes — ¿Cuánto cuesta implementar inteligencia artificial en una pyme?
https://ia4pymes.tech/blog/cuanto-cuesta-implementar-inteligencia-artificial-pyme-precios - Mottum — Cómo implementar IA en tu pyme sin perder tiempo ni dinero
https://mottum.io/es/blog/como-implementar-ia-en-tu-pyme-sin-perder-tiempo-ni-dinero/ - Xpertix — RAG empresarial para pymes: implementación paso a paso
https://xpertix.com/rag-empresarial-pymes-implementacion-paso-a-paso/ - Jacar — vLLM: cómo servir LLMs en producción
https://jacar.es/vllm-servir-llm-produccion/ - Utilia — Costes de IA para pymes en 2025
https://utilia.ai/es/blog/cuanto-cuesta-ia-pymes-2025
No responses yet